
 by
by In this lesson, you will learn about Bias/Variance Trade-off in Machine Learning.
This is a concept in machine learning which refers to the problem of minimizing two error sources at the same time and this prevents the supervised learning algorithms from generalizing to accommodate inputs beyond the original training set.
We would discuss the following:
- What is Bias/Variance Tradeoff (Definition)?
- Sources of Error
- Bias/Variance Decomposition of Squared Error
- Trade-off: Minimizing Error
- Relationship to Underfitting and Overfitting
- Illustration of Bias-Variance Trade-off
- The Bias/Variance Trade-off Graph
- Summary and Final Notes
1. Definition of Bias-Variance Trade-off
First, let’s take a simple definition. Bias-Variance Trade-off refers to the property of a machine learning model such that as the bias of the model increased, the variance reduces and as the bias reduces, the variance increases.
2. Sources of Error
We recall the problem of underfitting and overfitting when trying to fit a regression line through a set of data points.
In case of underfitting, the bias is an error from a faulty assumption in the learning algorithm. This is such that when the bias is too large, the algorithm would be able to correctly model the relationship between the features and the target outputs.
In case of overfitting, variance is an error resulting from fluctuations int he training dataset. A high value for variance would cause the algorithm may capture the most data points put would not be generalized enough to capture new data points. This is overfitting.
The trade-off, means that a model would be chosen carefully to both correctly capture that regularities in the training data and at the same time be generalized enough to correctly categorize new observation
3. Bias-Variance Decomposition of Squared Error
Considering the squared loss function and the conditional distribution of the training data set, we could summarize the formula for the expected loss to be:
Now assuming y = f(x) representing the true relationship between the variables in the training data set
Also let function f'(x) which is an approximation of f(x) through the learning process
Then we measure the mean squared error between y and f'(x) which is given as:
(y – f'(x))2.
This error is expected to be minimal.
We than then write the original expected loss equation as:
E[(y – f'(x))2] = Bias[f'(x)]2 + Var[f'(x)] + σ2
where:
Bias[f'(x)] = E[(f'(x) – f(x)]
and
Var[f'(x)] = E[f'(x)2] – E[f'(x)]2
and
σ2 represents the noise term in the equation
4. The Bias/Variance Tradeoff
The objective is to reduce the error E to the minimum. This can be done by modifying the terms of the mean square error. From the equation, we see that we could only modify the bias and the variance terms.
Bias arises when we generalize relationships using a function, while variance arises when there are multiple samples or input.
One way to reduce the error is to reduce the bias and the variance terms. However, we cannot reduce both terms simultaneously, since reducing one term leads to increase in the other term. This is the idea of bias variance trade/off.
5. Relationship with Underfitting and Overfitting
A good model should do one of two things
- Capture the patterns in the given training data set
- Correctly compute the output for a new instance
The model should be complete enough to represent the data, but the more complex the model, the better it represents the training data. However, there is a limit to how complex the model can get.
If the model is too complex, then it will pick up specific random features (noise or example) in the training data set.
If the model is not complex enough, then it might miss out on important dynamics of the data given.
The problem where the model chosen is too complex, and becomes specific to the training data set is called overfitting.
The problem where the model is not complex enough and misses out on the important features of the data is called underfitting.
It is generally impossible to minimize the two errors at the same time and this trade-off is what is known as bias/variance trade-off.
6. Illustration of Bias-Variance Trade-off
Assuming you have several training data sets for the same population:
- Training Data 1
- Training Data 2
- Training Data 3
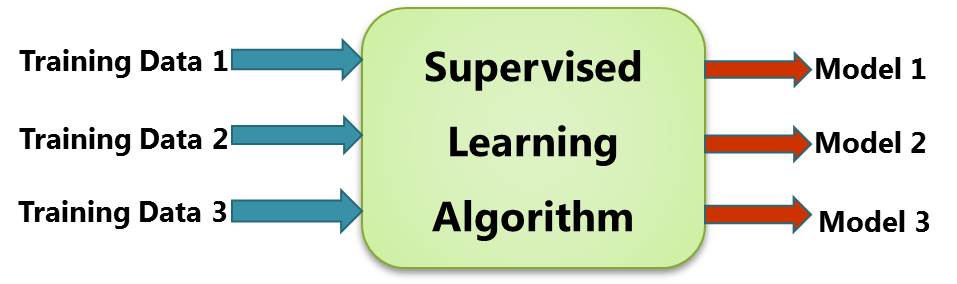 |
| Figure 1: Supervised Learning algorithm |
These three data sets are passed through the same supervised learning algorithm which produces three models.
- Model 1
- Model 2
- Model 3
Now, let say we want to predict the output of a new input x, The three models should be able to produce the same output for the same new instance. But when you pass x into each of the models, instead of getting the same output, you get a different output(y1, y2 and y3) for the same x.
This is illustrated in Figure 2.
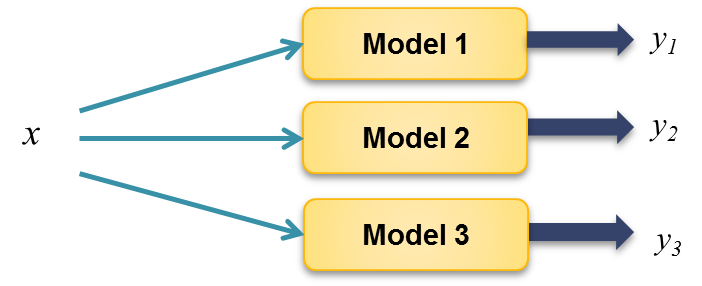 |
| Figure 2: High Variance Error |
The problem here is that that the model have become too specific that it cannot capture the correct output for a new value for x.
In this case, the algorithm is said to have high-variance error. Which results in a problem of overfitting.
Let’s also assume that, you pass different values of x (x1, x2 and x3) into the same model. Instead of getting different outputs, you get the same output y. In this case, the algorithm is said to have high bias error, which results in a problem of underfitting. This is illustrated in Figure 3 below:
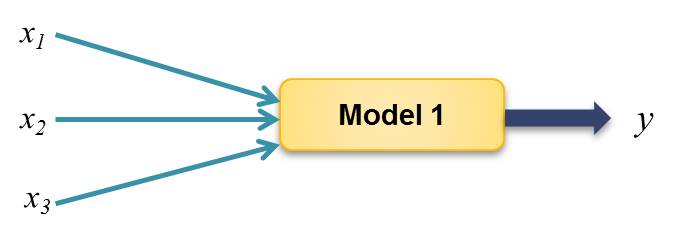 |
| Figure 3: High Bias Error |
High variance means that the algorithm have become too specific.
High bias means that the algorithm have failed to understand the pattern in the input data.
It’s generally not possible to minimize both errors simultaneously, since high bias would always means low variance, whereas low bias would always mean high variance.
Finding a trade-off between the two extremes is known as Bias/Variance Tradeoff.
7. Explanation of the Bias/Variance Graph
The graph in Figure 3 is a typical plot of the bias/variance trade-off which we would briefly examine.

The bias/variance graph shows a plot of Error against Model Complexity. It also shows:
Relationship of variance and Model Complexity: As we increase the variance, the variance increases
Relationship of bias and Model Complexity: As the bias increase, the model complexity reduces
Relationship of variance and Error: As the variance increases, the error increases.
Relationship of bias and Error: As the bias increases, the error increases.
8. Final Notes
With the above assumption, we could go ahead to derive the bias-variance decomposition for squared error but that would be in a different lesson.
Thank you for reading and do remember to leave a comment if you have any challenges following the explanation.


{kind=link}
[…] too extremes we just discussed. This trade-off has a special name in Machine Learning. It is called Bias-Variance Trade-off. It would be discussed further is subsequent lectures. Bias-Variance Trade-off […]
[…] also recommend you read my previous article on Bias-Variance Trade-off. It gives a mode detailed […]
[…] also recommend you read my previous article on Bias-Variance Trade-off. It gives a mode detailed […]