In this lesson, we are going to examine classification in machine learning. Below are the topics we are going to cover in this lesson
- Formulation of the Problem
- The Cancer Diagnosis Example
- The Inference and Decision Problems
- The Role of Probability
- Minimizing Rate of Misclassification
- Minimizing Expected Loss
- Approaches to Classification bases on a Priori Knowledge
So let’s begin with the first one
1. Formulation of the Problem
Suppose we have an input vector x together with a corresponding vector t of the target variable. This set of input vector x, and target vector t forms the training data set.
Now, the goal is to predict t for a new value of x. For classification problem, t would represent class labels. The joint probability distribution p(x, t) provides a complete summary of the uncertainty associated with these variables. Determination of this probability from the training data set is an example of inference problem
2. The Cancer Diagnosis Example
Let’s take the example of the medical diagnosis problem where we need to determine whether or not the patient have cancer. An x-ray image of the patient is taken, so the input vector x is a set of pixel intensities of the x-ray image.
The output variable t will represent the presence or absence of cancer. Now we can form two classes C1 and C2. C<sub1 represents the presence of cancer while C2 represents the absence of cancer.
We need to assign the input to one of the two classes.
3. The Inference and Decision Problems
The general inference involves determining the joint distribution p(x, Ck), or p(x,t), which give the most complete probabilistic description of the problem. This is the inference step.
After this, a decision is made whether to give treatment or not. This is the decision step. This step becomes easy if the inference problem have been solved.
4. The Role of Probability
When the x-ray images is obtained x for a new patient, the goal is to determine which of the two classes to assign the image.
We could assign it to any of the two classes, C1 or C2 (let’s use Ck, for k = {1,2}). We need to find the probabilities of the two classes given the image. This probability is given by p(Ck | x). Using Bayes theorem, these probabilities can be expressed in the form:
5. Minimizing Misclassification
Sometimes in classification, we may assign an input to the wrong class. In this case, misclassification have occurred. The goal is to make as few misclassifications as possible.
Misclassification occurs when an input variable is assigned to the wrong class. The goal is to minimize the number of misclassifications.
We handle this by creating a rule that assigns each x to one of the available classes. This rule would divide the input space into regions Rx called decision regions, one region for each class.
Points in Rx are assigned to Ck.
A misclassification when a point in a region is assigned to the wrong class e.g
- x is in R1 but is assigned to class C2
- x is in R2 but is assigned to class C1
The probability of misclassification is given by:
To minimize this error, the rule must assign x to which class has minimum integrand:
p(x, Ck) = p(Ck | x)p(x)
From the above formula, to minimize misclassification, x should be assigned to which class the posterior probability is largest.
6. Reducing Expected Loss
The case of cancer diagnosis shows that a loss incurred when there is misclassification could be of different degrees.
So we introduce a loss function or cost function E(L).
Suppose that for a new value of x, the correct class is Ck but we assign it to Cj (where j k). In this case, we have incurred some loss Lkj.
where k and j are elements of the loss matrix, (as in the case of cancer diagnosis).
The optimal solution is the one that minimizes the value of the loss function.
The average loss depends on the joint probability p(x, Ck) and is given by:
The objective is to choose Rj in order to minimize the expected loss. If we know the posterior probability p(Ck, x), then we can minimize the loss.
7. Three Approaches to Classification
The three approaches to classification are:
- Determination of the class conditional probabilities
- Determination of the posterior probability directly
- Use a Discriminant function
a. Determine the Class Conditional Probabilities
Determine the Class Conditional Probabilities p(x|Ck) for each class. Then determine the prior probabilities p(Ck) for each class. Then using Bayes theorem, determine the posterior probability.
b. Directly Determine the Posterior Probabilities
Solve the inference problem by first obtaining the posterior class probabilities p(Ck |x) for each class. Then use decision theory to assign new values of x to classes.
c. Use a Discriminant Function
Find a function f(x) called a discriminant function that would map each input directly to a class label. For example:
 by
by 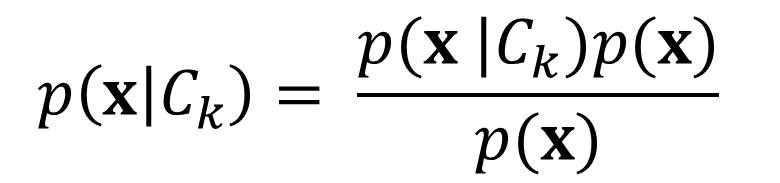
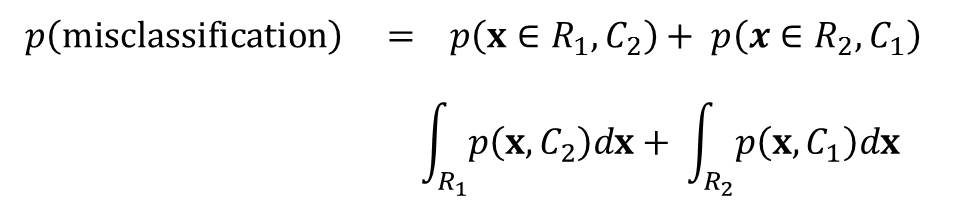
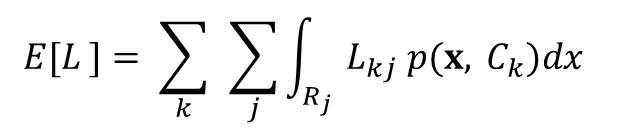
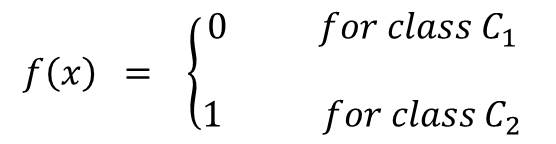
Thanks , I’ve just been looking for info about this subject for ages and yours is the best I’ve discovered so far. But, what about the conclusion? Are you sure about the source?