 by
by - Introduction to Clustering
- Formalized Definition of k-Means Clustering
- 1-of-K Coding Scheme
- The Expectation and Maximization Algorithm

Introduction to Clustering
Clustering is a class of unsupervised learning concept or machine learning whose goal is to identify groups or clusters within datapoints in a multi-dimensional space.
Suppose we have data sets {x1, x2, …, xn} consisting of N observations of a random D-dimensional Euclidean variable x. The goal is to partition the data into K clusters when the value of K is preknown.
We can define a cluster as a group of data points whose inter-point distances are minimal compared with the distance with points that are outside the cluster.
Formalization of k-Means Clustering
Let’s assume a set of D-dimensional vectors μk where k = 1, 2, …, K and μk represents the centroid of the cluster k. Take centroid to be the mean of data points in the cluster.
Our goal is to find the assignment of data points to clusters as well as a set of vectors { μk} such that the sum of squares of distances of each data point to its closest vector μk is at a minimum.
1-of-K Coding Scheme
The 1-of-k Coding Scheme is a coding scheme applied to a K-dimensional vector x in which one of the elements xk equals 1 and all the remaining elements 0. This means that a data point cannot belong to two clusters at the same time.
In this case, for each data point x, we introduce a corresponding set of binary indicator variables rnk ∈ {0,1}.
If xn is assigned to μk then rnk = 1 and rnj = 0 for j ≠ k
We can then define an objective function J know as distortion measure
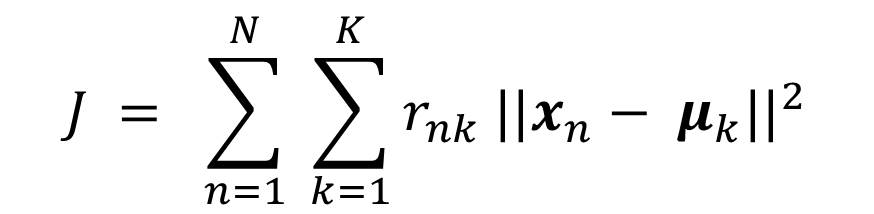
This represents the sum of the squares of the distances of each of the data points from its assigned vector μk
The goal is to choose values for {rnk} and {μk} so as to minimize J. This brings us to the next section where we would examine the algorithm.
The Expectation and Maximization Algorithm(k-Means)
The algorithm is an iterative algorithm where for each iteration, two steps are taken that optimizes the variables rnk and μk
The algorithm goes this way.
First, choose an initial value for μk
In the first phase: we minimize J with respect to rnk while keeping μk fixed.
In the second phase, we minimize J with respect to μk while keeping rnk fixed.
Repeat the two steps until convergence.