 by
by - Classification and
- Clustering

I have decided to create this article because of the confusion the name of the topics may pose. Is clustering not the same as classification, like having to separate the data into different classes or clusters? It seems to make sense, right?
But, in the world of machine learning, the two are completely different concepts.
Let’s start the discussion with classification.
What is Classification?
First classification is a supervised learning technique that has to do with learning and training an algorithm using a set of labeled training input dataset.
In classification, the goal is to assign each input vector to one of a finite number of discrete categories.
Real life application of classification is spam detection. In this case, there are finite number of discrete categories an email can belong to: spam and non-spam. The input data set in this case is incoming emails.
Theory of Classification
Assuming that we are given a training set comprising of N observation of random variable X which can have values of x1, x2, … ,xn.
Then we also have corresponding observations of the values of t, which can take values t1, t2, … ,tn.
The first step would be to find the function of x that maps the input x to the corresponding t.
To do this we can use the polynomial curve fitting which is of the form:
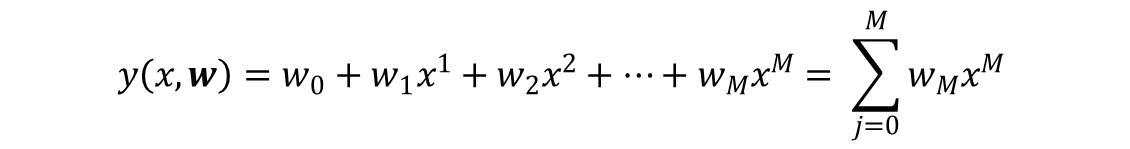
We would not go further than this since we are only considering difference between classification and clustering.
Find a detailed discussion of classification on:
Introduction to Machine Learning
Difference between Classification and Regression
What is Clustering?
Clustering is an unsupervised learning technique whereby the input dataset is unlabeled.
In clustering, we use a finite set of input data, and to goal is to discover, groups(or clusters) within the data that have similar characteristics.
Theory of Clustering
Assuming we have a set of observations {x1, x2,… xn} which consists in a set of N random variable x (x is a D d-dimensional real vector). The goal is to partition the data set into some number K of clusters, where the value of K is known.
A cluster is a group of data points whose inter-point distances are minimal when compare with distance to points outside the cluster.
The first step is to find the mk, for k = 1,…, K, in which mk is the mean associated to the kth cluster.
We now assign each of the data points to clusters, such that the sum of squares of the distances of each data point to its closest mean mk is minimum.This particular case is known as k-means clustering.
Find detailed explanation on: K-Means Clustering.
Summary of differences between Classification and Clustering is given below:

