What is Maximum Likelihood(ML)? and What is Maximum Likelihood Estimation (MLE)?
These is a very important concept in Machine Learning and that is what we are going to cover today.
Table of Content
- What is Maximum Likelihood Estimation(MLE)?
- Properties of Likelihood Extimates
- Deriving the Likelihood Function
- Log Likelihood
- Applications of MLE
- Final Thoughts
1. What is Maximum Likelihood Estimation?
The likelihood of a given set of observations is the probability of obtaining that particular set of data, given chosen probability distribution model.
MLE is carried out by writing an expression known as the Likelihood function for a set of observations. This expression contains an unknown parameter, say, θ of he model. We obtain the value of this parameter that maximizes the likelihood of the observations. This value is called maximum likelihood estimate.
Think of MLE as opposite of probability. While probability function tries to determine the probability of the parameters for a given sample, likelihood tries to determine the probability of the samples given the parameter.
2. Properties of Maximum Likelihood Estimates
MLE has the very desirable properties especially for very large sample sizes some of which are:
likelihood function are very efficient in testing hypothesis about models and parameters
they become unbiased minimum variance estimator with increasing sample size
they have approximate normal distributions
3. Deriving the Likelihood Function
Assuming a random sample x1, x2, x3, … ,xn which have joint probability density and denoted by:
L(θ) = f(x1, x2, x3, … ,xn|θ)
where θ is a parameter of the distribution with unknown value.
We need to find the most likely value of the parameter θ given the set observations. To do this, we use a likelihood function.
The likelihood function is defined as:
L(θ) = f(x1, x2, x3, … ,xn|θ)
which is considered as a function of θ
If we assume that the sample is normally distributed, then we can define the likelihood estimate for θ as the value of θ that maximizes the L(θ), that is the value of θ that makes the data set most likely.
We can split the function f(x1, x2, x3, … ,xn|θ) as a product of univariates such that:
L(θ) = f(x1, x2, x3, … ,xn|θ) = f(x1|θ) +f(x2|θ), + f(x3|θ) +… + f(xn|θ)
which would give us the same results.
So the question is ‘what would be the maximum value of θ for the given observations? This can be found by maximizing this product using calculus methods, which is not covered in this lesson.
4. Log Likelihood
Maximizing the likelihood function derived above can be a complex operation. So to work around this, we can use the fact that the logarithm of a function is also an increasing function. So maximizing the logarithm of the likelihood function, would also be equivalent to maximizing the likelihood function.
This is given as:
So at this point, the result we have from maximizing this function is known as ‘maximum likelihood estimate‘ for the given function
5. Applications of Maximum Likelihood Estimation
MLE can be applied in different statistical models including linear and generalized linear models, exploratory and confirmatory analysis, communication system, econometrics and signal detection.
6. Final Thoughts
Also it is important to note that calculating MLEs often requires specialized computer applications for solving complex non linear equations. However such tools are readily available.
I would recommend making some effort learning how to use your favorite maths/analytics software package to handle and MLE problem
 by
by 
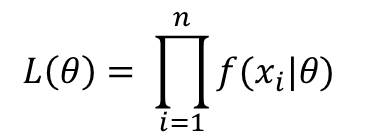
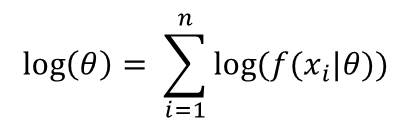
[…] Maximum Likelihood Estimation is a procedure used to estimate an unknown parameter of a model. MLE is based on the Likelihood Function and it works by making an estimate the maximizes the likelihood function. The likelihood function is simply a function of the unknown parameter, given the observations(or sample values). Therefore, maximum likelihood estimate is the value of the parameter that maximizes the likelihood of getting the the observed data. […]
There are two typos in the blog:
1-> You have used addition sign + instead of multiplication sign * in deriving the likelihood function paragraph
2->In the same paragraph you have written that we have to find maximum theta(parameter) instead we have to find such theta for which the likelihood function gives maximum value.